How to Scrape Facebook Page Posts and Comments to Excel (with Python)
129")
In this tutorial, I will show you how to easily scrape any public Facebook Page or Group posts and comments to Excel spreadsheet using Facebook scraper tool(ready-made Python Scripts).No programming background is required but might be helpful.Just follow the easy steps.
Once you feed in the required information at the command line prompt (Facebook access token and Page name or Group ID) and command it to run it will automatically download the following data from the Facebook Page or Group to Excel spreadsheet:
- All the Facebook statuses or posts of the page or group
- The number of likes,shares and comments for each post
- The number of Facebook reactions (Like,Love,Haha,Wow,Sad,Angry) for each post
- Each post status type,link and published date
- All the comments with comment’s author and number of likes for each comment(if any),published date
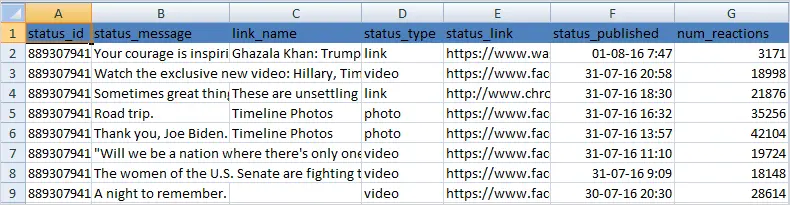
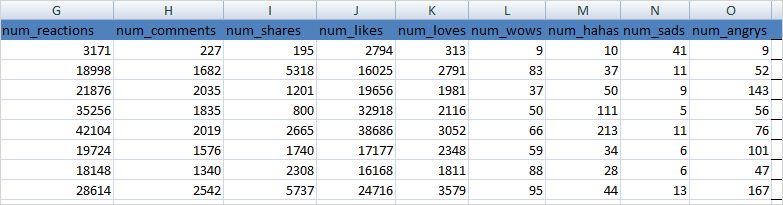
Below images show Facebook statuses/Posts extracted from Hillary Clinton Facebook page using the scripts:
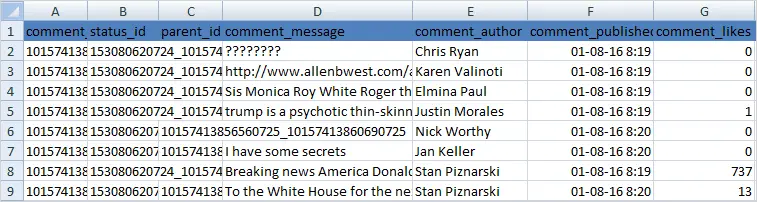
Below image shows Comments extracted from Donald Trump Facebook page using the scripts:
Let’s get started.
Table of Contents
- 1 Step 1:Install Python 2
- 2 Step 2:Get access token from the Facebook Graph API explorer
- 3 Step 3:Getting Facebook Page name or Group ID
- 4 Step 4:Scraping Facebook Page posts data such Post statutes,Reactions count,Likes count,Shares count,comments count
- 5 Step 5:Scraping Facebook Group posts data such as Post statutes,Reactions count,Likes count,Shares count,comments count
- 6 Step 6:Downloading Facebook Pages and Groups posts comments to Excel
- 7 Step 7: Scraping single post comments and names of people who like the post: Perfect for running Facebook contests
- 8 Conclusion and recommendations
Step 1:Install Python 2
Since we will be using Python scripts to extract data from the Facebook page then we need to install Python interpreter to execute them.Installation instructions will vary depending on whether you are using Mac OS X,Linux/UNIX or Windows.I will cover the installation in brief.But it is very easy and there is a lot of detailed instructions online incase you can’t follow my brief explanation.If you have Python already installed on your system you can skip this step.
For Windows computers
If you don’t have Python 2 on your system follow below steps:
- Download Python 2.7.x and install it (Don’t install Python 3 the scripts won’t work).
- After Python is installed.Search PowerShell from the Start menu and press Enter to run it.
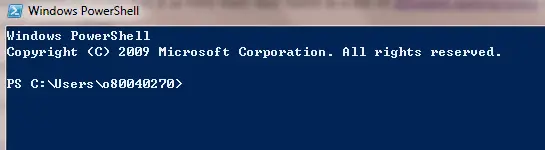
- In the PowerShell window type python (in lower case) and hit RETURN/ENTER key as shown in the image below:
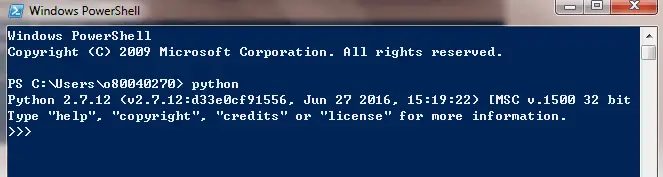
- After hitting return the version of Python which is installed on your system will show.In my case, I have Python 2.7.12 installed on my Windows.
- If it says “Python is not recognised” which will, fortunately, happen if you run Python for the first time on windows.Then in PowerShell copy and paste below values,Close the PowerShell then start it again to make sure Python now runs and repeat Step 3. [Environment]::SetEnvironmentVariable(“Path”, “$env:Path;C:Python27”, “User”)
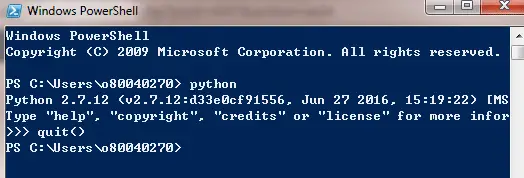
- Type quit(), Enter, and get out of python.You should be back at a prompt similar to what you had before you typed python. Then move to Step 2.
For Mac OS X and Linux/UNIX computers
If you are using Mac OS X computers Python 2 is already pre-installed.Also, most Linux/UNIX systems have Python 2 pre-installed.If not installed you can install it from command line by writing brew install python but make sure you have brew installed on your MAC.

- If you are using Mac OS X or Linux system search for Terminal program,once it is open type python (in lower case) and hit RETURN/ENTER key as shown in the image below:
- After hitting return the version of Python which is installed on your system will show.In my case I have Python 2.7.6 installed.If it doesn’t show you anything then you have to go to Python Website and download Python 2.7.x (Don’t install Python 3 the scripts won’t work)
- Type quit(), Enter, and get out of python.You should be back at a prompt similar to what you had before you typed python. Then move to Step 2.
Step 2:Get access token from the Facebook Graph API explorer
The Python scripts will access data from Facebook using the Facebook Graph API.You will need to fill in the access token so that the scripts are authenticated to extract data through the API.
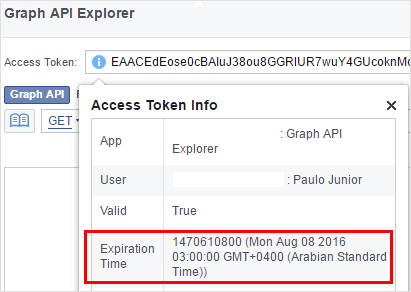
You get the access token by visiting Facebook Graph Explorer,then sign in with your Facebook account(any).Get the access token as shown in the image below and save it somewhere as we will need it in later steps.
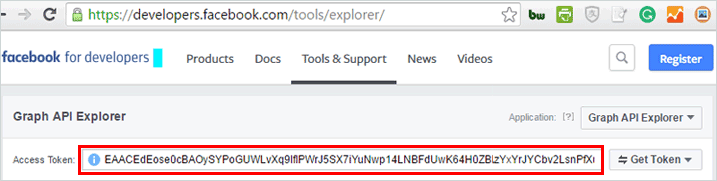
Normally the access token is valid for 2 hours before it can expire.If it expires you can click “Get Token” to get a new one.
An access token which never expires
You can create an access token which never expires by concatenating Facebook App ID and App Secret with a pipe.
To get Facebook App ID and App Secret, you must create a Facebook for Developers account. Don’t worry it so easy than it sounds. Click this link and follow the wizard. After setting up your app then go to your dashboard>settings>basic then click show App secret.

Your access token will be your app ID|app secret .Don’t forget the pipe “|” between the app ID and app secret. For example, my never expiring access token will be 1179322318819014|a5axxxxxxxxxxxxxxx.
Step 3:Getting Facebook Page name or Group ID
You can get a correct page name from the URL of the page as shown in the image below and save it somewhere as we will need the name later to scrape Facebook Page posts.

If you wish to scrape Facebook Open Groups then you need to get a numeric group ID and not a group name.
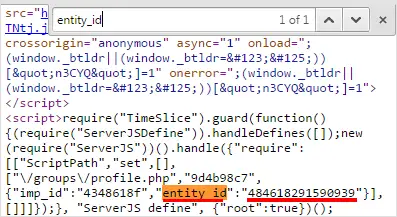
To get a numeric group ID,navigate to the Open group you wish to scrape and “view source”.To view source Press Ctrl + U (Windows, Linux) or Command + U (Mac) on the group page and search for entity_id or fb://group either one will have a number to that field.Copy the number and save it somewhere.
For example, the group ID of bigdatastatistics is 484618291590939.
Download posts.py script and save it somewhere on your computer.Put the script inside a folder.This is the same folder which the script will save the Excel spreadsheet after scraping.
Now from PowerShell for Windows and Terminal program for Mac OS X/Linux/UNIX navigate and open this folder containing your script.
For example, my script is saved inside “Scraping folder” on my desktop
Below is how I accessed the folder from the PowerShell
For example, my script saved inside “scraping folder” on the home directory on Ubuntu which will be similar to MAC OS X/Linux/UNIX
Below is how I accessed the folder from Ubuntu which will be similar to MAC OS X/Linux/UNIX
Now the interesting part is to run the script make sure the access token and Facebook page name or Group ID are with you as they will be the inputs for the scripts.
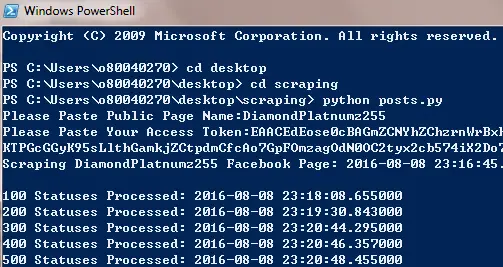
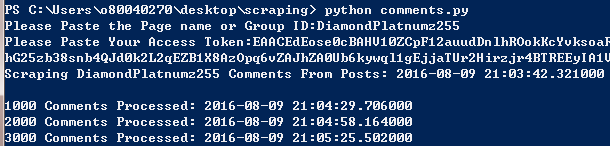
On the Windows PowerShell and Terminal program type python posts.py (make sure python is lower case).The script will start running and it will ask you to paste the Facebook Page ID.Paste it there and click ENTER/RETURN KEY.Then it will ask you to paste the access token.Paste it there and click ENTER/RETURN KEY.Make sure not to paste any extra whitespace as it might cause some error.
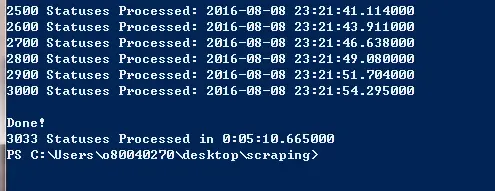
For example, I was scraping data from the Facebook Page DiamondPlatnumz255 and my access token started with EAACEdE(Truncated).It took only 5 minutes to scrape 3033 posts statuses as shown below:
When the script finishes running it will give you a final report showing how many statuses were processed and how much time it took.
The Statuses will be saved in the folder where your script resides as a CSV file.The CSV format can be opened by MS Excel program in Windows.
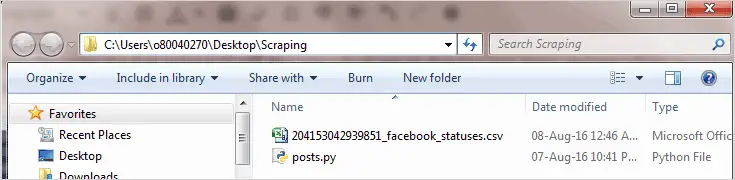
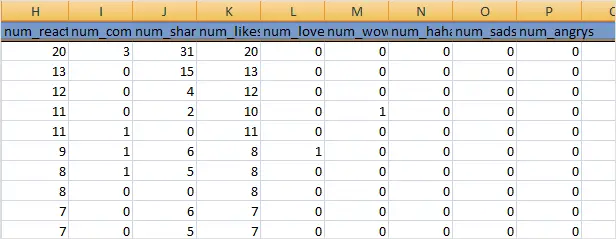
The CSV will have the following columns of data “status_id”, “status_message”, “link_name”, “status_type”,”status_link”,”permalink_url”, “status_published”, “num_reactions”, “num_comments”, “num_shares”, “num_likes”, “num_loves”,”num_wows”, “num_hahas”, “num_sads”, “num_angrys”
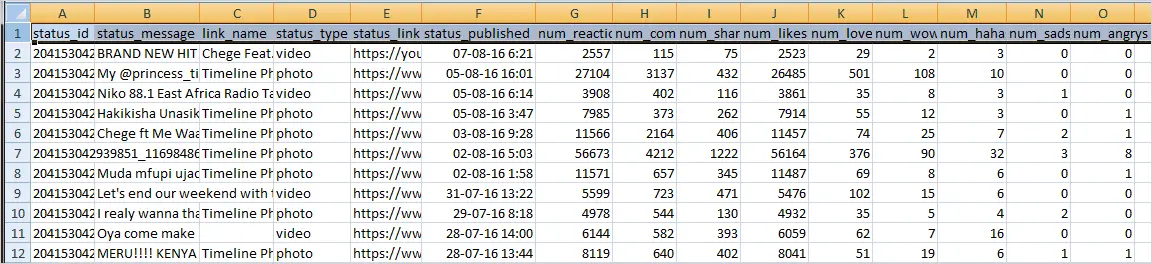
Sometimes you might encounter some errors especially (HTTP Error 400:Bad Request) if the access token is expired.The script will keep on retrying.To terminate the script hit CTRL+C.
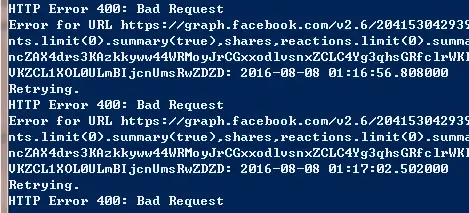
If you encounter the above error.Check to see if the access token is not expired.If it is expired you can get a new one by refreshing the Graph API explorer or create a never expiring access token.
Scraping Facebook Open Public groups is similar to scraping Facebook pages.Make sure you have the Group numeric ID as explained in Step 3 and access token as explained in Step 2.Then run this Python script groups.py as explained in Step 4.
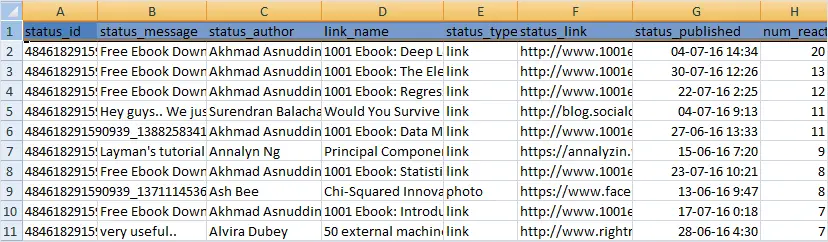
Below is an output after scraping a Public Group bigdatastatistics with a Group numeric ID of 484618291590939.
The output CSV will have these columns of data “status_id”,”status_message”, “status_author”,”link_name”, “status_type”, “status_link”,”permalink_url”,”status_published”, “num_reactions”, “num_comments”,”num_shares”, “num_likes”, “num_loves”, “num_wows”,”num_hahas”, “num_sads”, “num_angrys
Step 6:Downloading Facebook Pages and Groups posts comments to Excel
To scrape all the user comments from Facebook pages or groups posts make sure the output CSVs you got from previous steps exist because the python script will read status_id from the CSV files obtained in the previous steps and use the data to generate comments.
Download the script comments.py run it and it will ask you for the Facebook Page name or Group ID>Put the same name or group ID as you used in the previous steps,then put the access token.
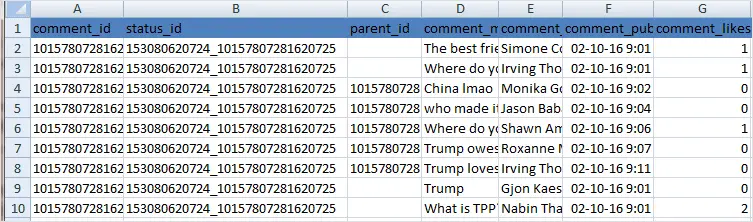
The output CSV file will have these columns of data “comment_id”, “status_id”, “parent_id”, “comment_message”,”comment_author”,”comment_published”, “comment_likes”
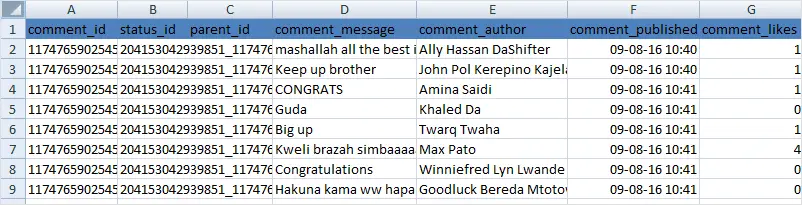
The output CSV file includes a column with status_id.The status_id column is also included in the output we got while scraping Facebook page or group in the previous steps.So you can map the comment to the original Post with a JOIN or VLOOKUP, and also a parent_id if the comment is a reply to another comment.
Keep in mind that active Facebook pages or Groups have a lot of comments.The throughput of this script is approximately 87k comments/hour.
Step 7: Scraping single post comments and names of people who like the post: Perfect for running Facebook contests
In step 6, I showed you how to extract comments from all the statuses of a Facebook page but in this step, I will show you how to export comments to CSV for a single post of your choice.

Open pagename_facebook_statuses.csv generated in step 5, remove all the rows with the posts you don’t want to get comments from and keep only the row with the post you want to get comments from.Then run again the comments.py . The comments for a single post will be saved in CSV.
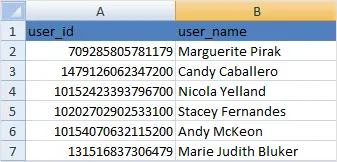
What if you want to get the names of the people who like that post?
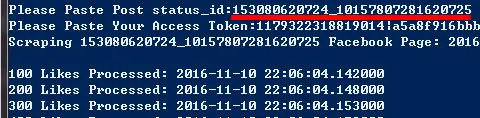
Copy the post’s status_id somewhere then run this likes.py script. The script will ask you for a post status_id paste the post’s status id. For my case the status_id is 153080620724_10157807281620725 . See how I pasted below.
You will get a CSV that looks like below.
Conclusion and recommendations
I have tried to explain clearly the steps with images so that even if you are not coming from programming background you will be able to scrape data from Facebook.Incase you have any question please leave a comment below or you can contact me through the contact form.
You might also be interested in How to extract Twitter tweets data and followers to Excel
If you are not familiar with Python or have an experience in other programming languages and would like to learn Python I recommend you read this Python book. Python is an easy to learn programming language.
